
1. Download our demo here. Last update on 12/22/2016.
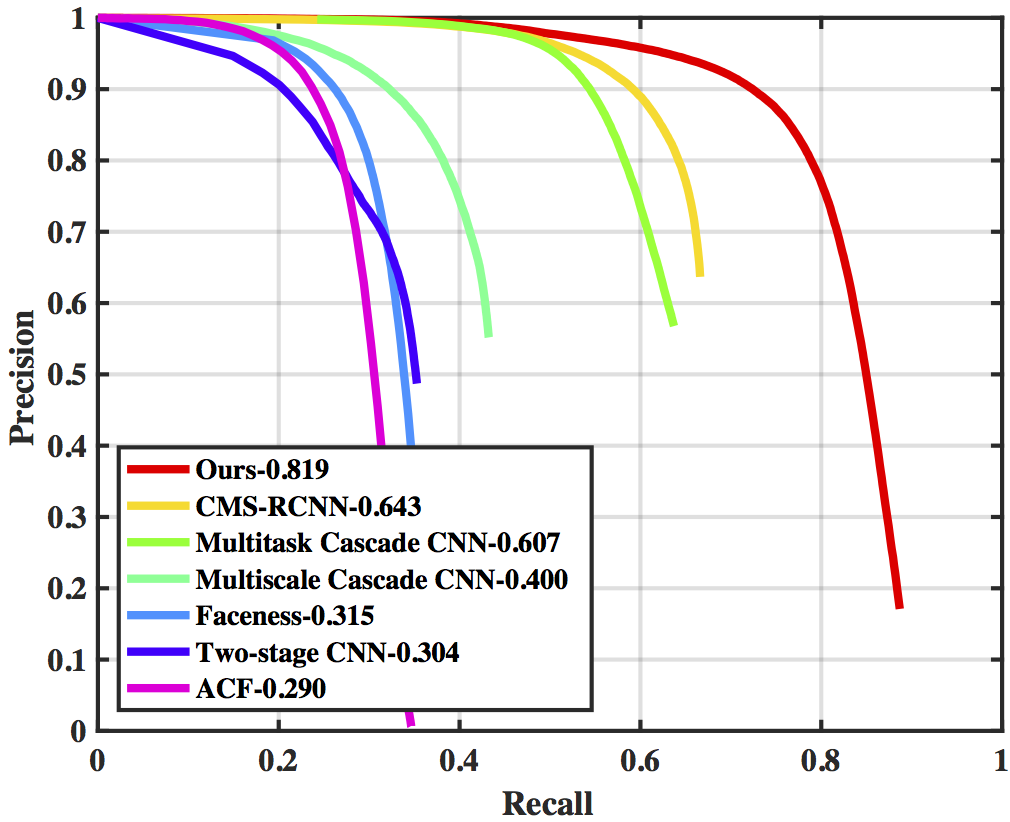
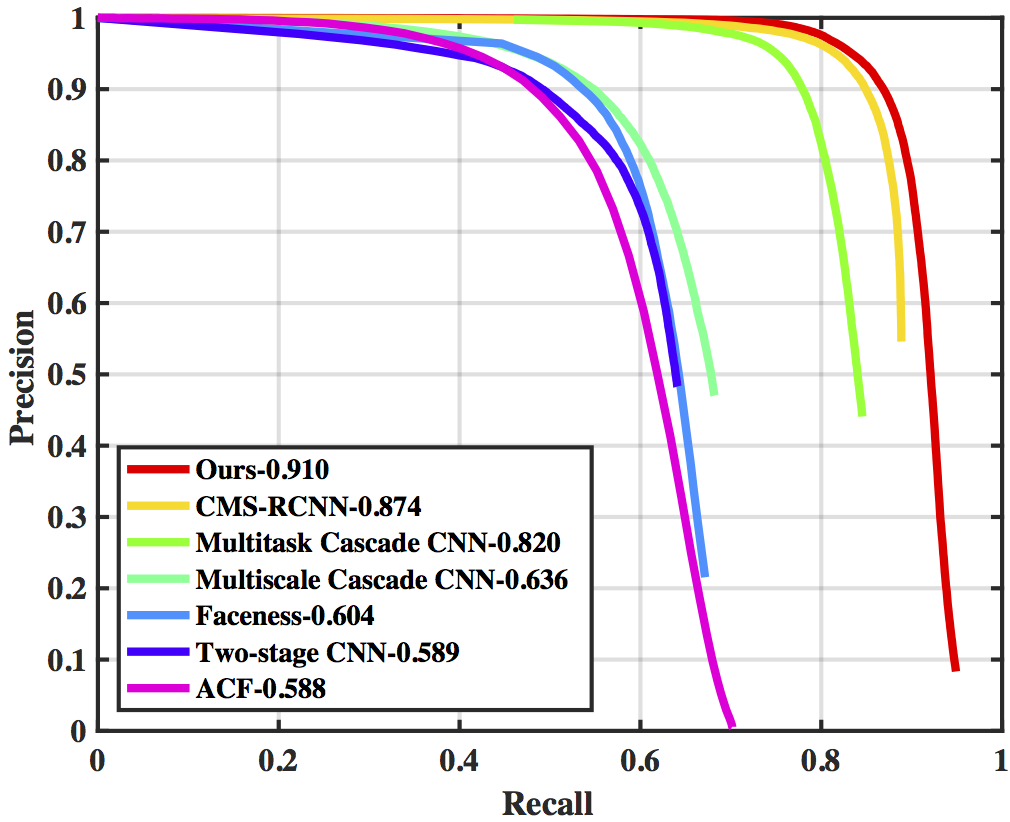
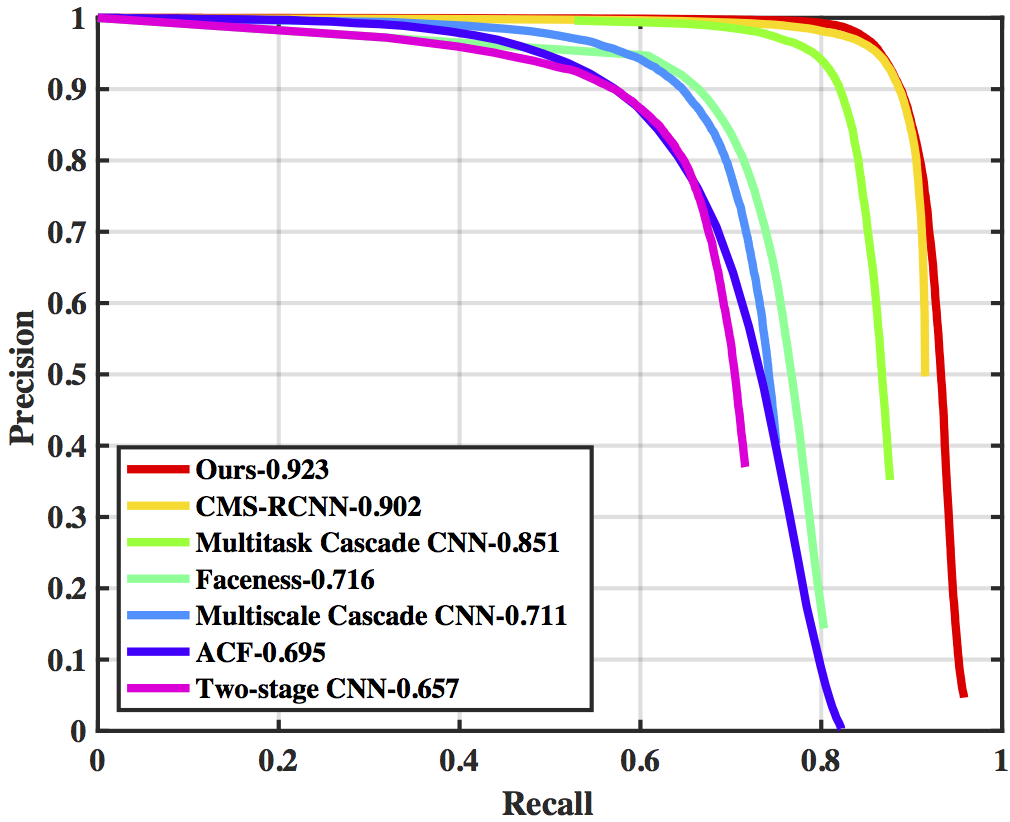
Though tremendous strides have been made in object recognition, one of the remaining open challenges is detecting small objects. We explore three aspects of the problem in the context of finding small faces: the role of scale invariance, image resolution, and contextual reasoning. While most recognition approaches aim to be scale-invariant, the cues for recognizing a 3px tall face are fundamentally different than those for recognizing a 300px tall face. We take a different approach and train separate detectors for different scales. To maintain efficiency, detectors are trained in a multi-task fashion: they make use of features extracted from multiple layers of single (deep) feature hierarchy. While training detectors for large objects is straightforward, the crucial challenge remains training detectors for small objects. We show that context is crucial, and define templates that make use of massively-large receptive fields (where 99% of the template extends beyond the object of interest). Finally, we explore the role of scale in pre-trained deep networks, providing ways to extrapolate networks tuned for limited scales to rather extreme ranges. We demonstrate state-of-the-art results on massively-benchmarked face datasets (FDDB and WIDER FACE). In particular, when compared to prior art on WIDER FACE, our results reduce error by a factor of 2 (our models produce an AP of 81% while prior art ranges from 29-64%).

Traditional approaches build a single-scale template that is applied on a finely-discretized image pyramid (a). To exploit different cues available at different resolutions, one could build different detectors for different object scales (b). Such an approach may fail on extreme object scales that are rarely observed in training (or pre-training) data. We make use of a coarse image pyramid to capture extreme scale challenges in (c). Finally, to improve performance on small faces, we model additional context, which is efficiently implemented as a fixed-size receptive field across all scale-specific templates (d). We define templates over features extracted from multiple layers of a deep model, which is analogous to foveal descriptors (e).
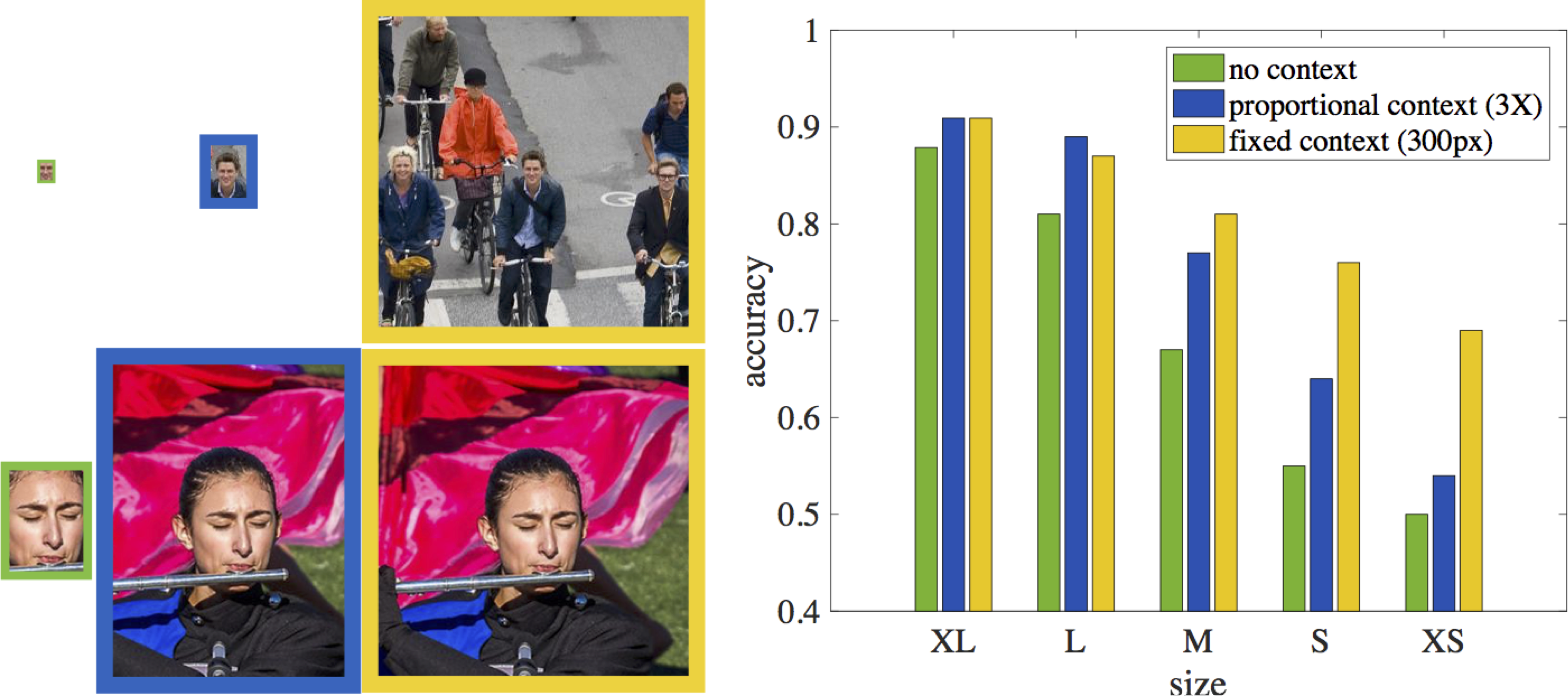
On the left, we visualize a large and small face, both without and with context. Context is not needed for a human user to recognize the large face, while the small face is dramatically unrecognizable without its context.
We quantify this observation with a simple human experiment (data) on the right, where users classify true and false positive faces of our proposed detector. Adding fixed context (300px) reduces error by 20% on small size (S) comparing to no context, but only 2% for extra large (XL). Also, proportional context (3X) becomes less helpful for smaller objects, suggesting context should also be modeled in a scale-variant manner. We operationalize this observation with foveal templates of massively-large receptive fields (around 300x300, the size of contextual images shown as as yellow boxes).
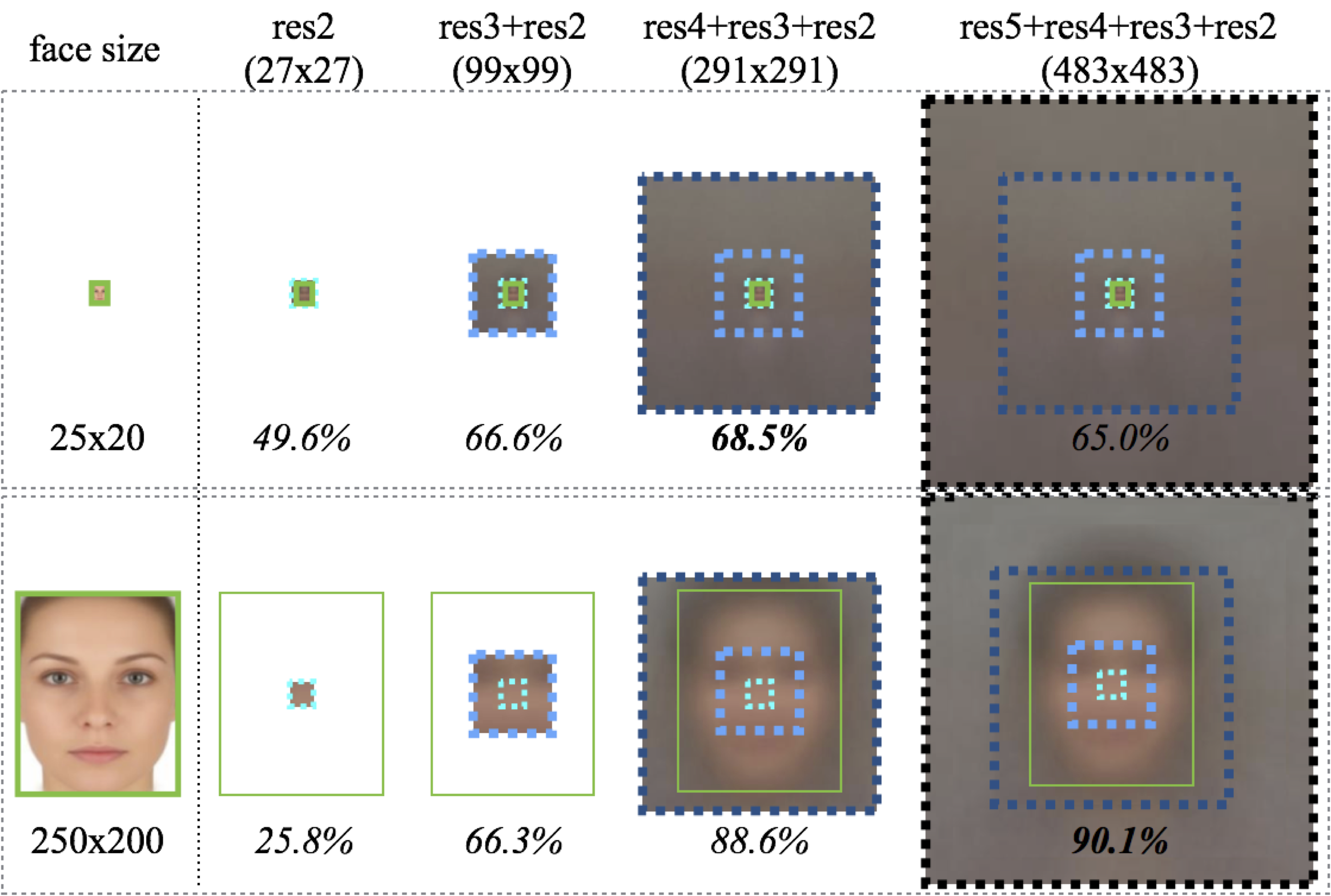
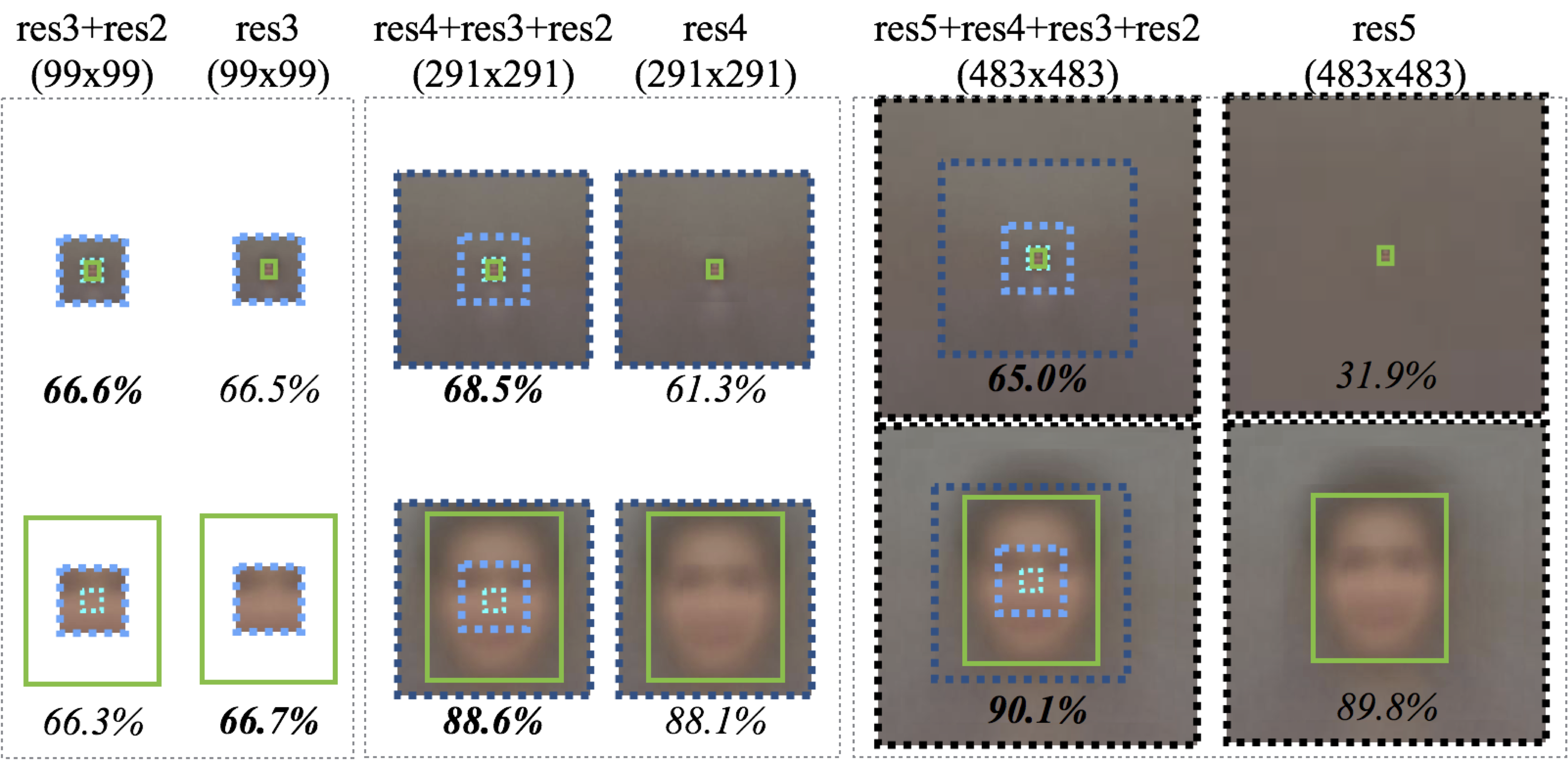
Modeling additional context helps, especially for finding small faces. The improvement from adding context to a tight-fitting template is greater for small faces (18.9%) than for large faces (1.5%). Interestingly smaller receptive fields do better for small faces, because the entire face is visible. The green box represents the actual face size, while dotted boxes represent receptive fields associated with features from different layers (cyan = res2, light-blue = res3, dark-blue = res4, black = res5). Same colors are used in Figures 5 and 7.
Foveal descriptors are crucial for accurate detection on small objects. The small template (top) performs 7% worse with only res4 and 33% worse with only res5. On the contrary, removing foveal structure does not hurt the large template (bottom), suggesting high-resolution features from lower layers are mostly useful for finding small objects!
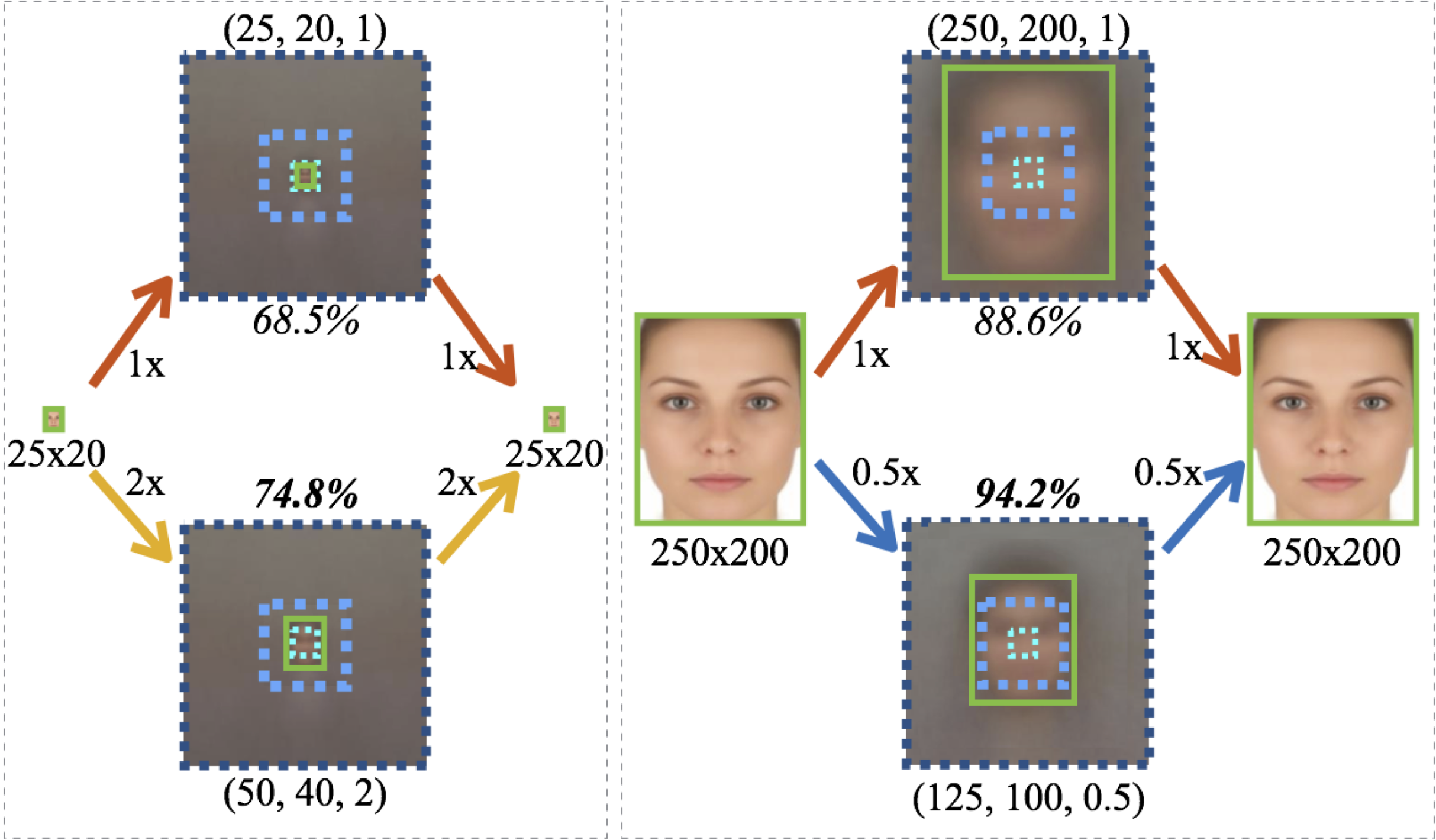
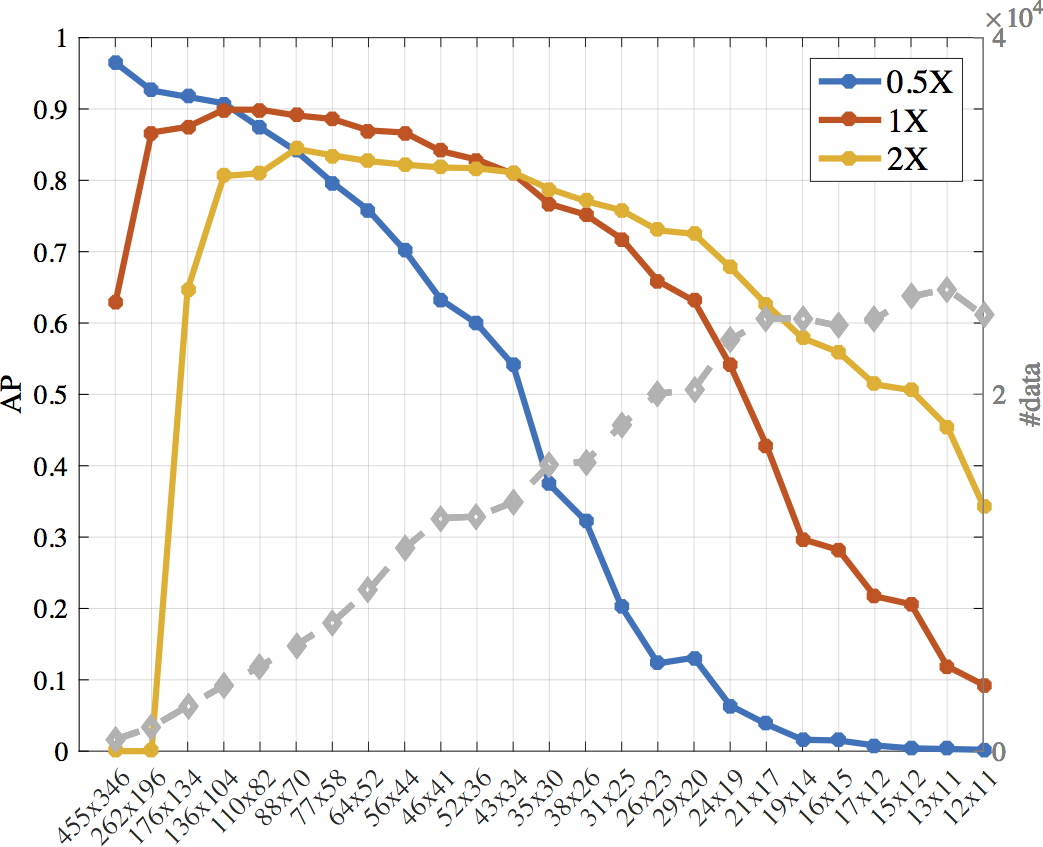
Say we want to find faces of 25x20 pixels. Surprisingly, we obtain better accuracy by using a 2X-larger template, of size 50x40 rather than 25x20. Alternatively, one can more accurately find 250x200 faces by using a 2X-smaller template, of size 125x100. Why?
We hypothesize that pre-trained models do not generalize to extreme scales. ImageNet has over 80% of its data between 40-140 pixel, considering a normalized world where images are all 224x2241. It is likely that pre-trained models are optimized for objects within such range of size. We've seen how to better generalize pre-trained networks for two specific scales. What about other scales?
We brute-forcely enumerate a number of scales, which roughly cover the scale space, and try three different strategies for every scale (shrink to 0.5X, stay as 1X, and interpolate to 2X). Natural regimes emerge in the figure: for finding large faces (more than 140px in height), build templates at 0.5X resolution; for finding small faces (less than 40px in height), build templates at 2X resolution. For sizes in between, build templates at 1X resolution.


We release the data used in the human experiment of our paper. The data contains both true positives and false positives of different scales and with different amount of context from our detector. Download it here.

We've released our training code plus a demo of our tiny face detector at https://github.com/peiyunh/tiny.
This research is supported in part by the Office of the Director of National Intelligence (ODNI), Intelligence Advanced Research Projects Activity (IARPA), via IARPA R&D Contract No. 2014-14071600012.
 Download Paper
Download Paper
{kind=link}
{kind=link}
{kind=link}