Bottom-Up and Top-Down Reasoning with Hierarchical Rectified Gaussians
CVPR 2016
Robotics Institute
Carnegie Mellon University

Abstract
Convolutional neural nets (CNNs) have demonstrated remarkable performance in recent history. Such approaches
tend to work in a “unidirectional” bottom-up feed-forward fashion. However, practical experience and
biological evidence tells us that
feedback plays a crucial role, particularly for detailed spatial understanding tasks. This work explores
“bidirectional” architectures that also reason with top-down feedback: neural units are influenced by both
lower and higher-level units.
We do so by treating units as rectified latent variables in a quadratic energy function, which can be seen
as a hierarchical Rectified Gaussian model (RGs). We show that RGs can be optimized with a quadratic program
(QP), that can in turn be optimized
with a recurrent neural network (with rectified linear units). This allows RGs to be trained with
GPU-optimized gradient descent. From a theoretical perspective, RGs help establish a connection between CNNs
and hierarchical probabilistic models.
From a practical perspective, RGs are well suited for detailed spatial tasks that can benefit from top-down
reasoning. We illustrate them on the challenging task of keypoint localization under occlusions, where local
bottom-up evidence may
be misleading. We demonstrate state-of-the-art results on challenging benchmarks.
Coarse-to-fine prediction
We visualize coarse-to-fine heatmap predictions, obtained by using multi-scale classifiers defined on
features extracted from multiple layers in our probabilistic model. Predictions based on only the
coarse-scale layer are identical. As one extracts features
from additional lower layers, the top-down model does a better job of incorporating contextual evidence,
which cleans up localization around the right knee and disambiguates the left/right ankle.
Low-level activation
Inspired by neurological experiments, we compare low-level activations at 0.5ms (during bottom-up processing) to the ones at 30ms (during top-down feedback). The convolutional activation of same neural units appears different after top-down feedback. Activation on facial parts (hair for top and facial skin for bottom) become stronger while activation on the background (including clothing) is suppressed. This is best shown with the average activation across images in the right-most column.
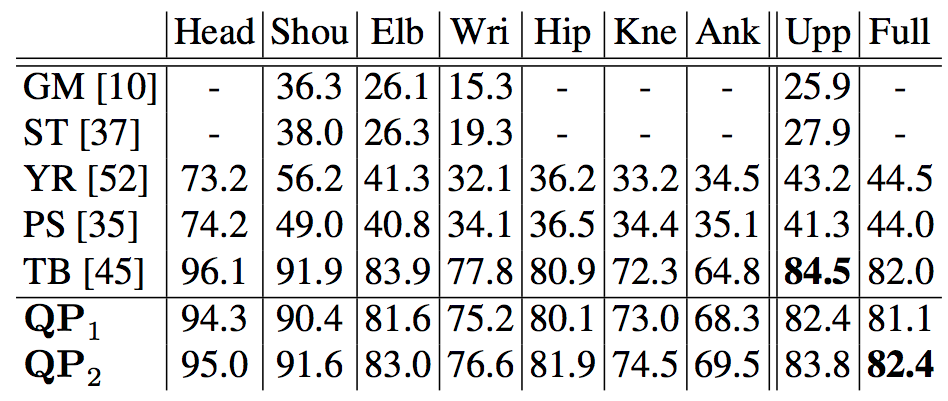
Human keypoint localization
Left are some human keypoint localization results produced by our proposed model. Top compares keypoint localization performance on MPII Human Pose between our approach and state-of-the-art at the time of submission. QP1 is equivalent to a "unidirectional" bottom-up feed-forward model, and QP 2 represents a "bidirectional" model with 2 passes of inference.
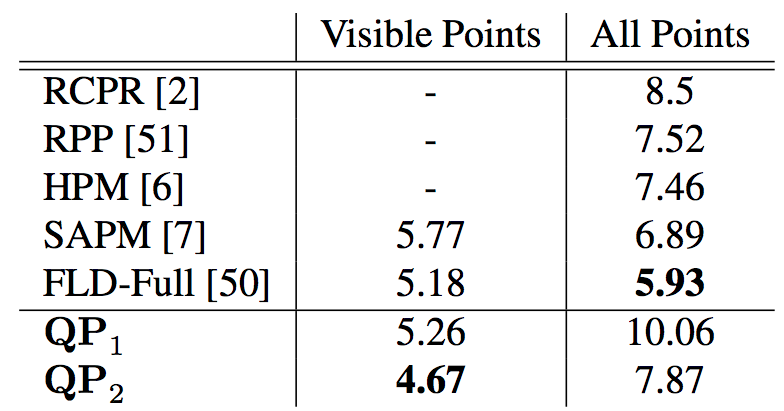
Facial landmark localization and visibility prediction
Left show examples of facial landmark localization plus visibility prediction (invisible and visible) from our model. Top compares keypoint localization performance on COFW between our approach and prior-art at the time of submission.
Code
We have released code and models for both human keypoint and facial landmark localization on Github.
Acknowledgments
This research is supported by NSF Grant 0954083 and by the Office of the Director of National Intelligence
(ODNI), Intelligence Advanced Research Projects Activity (IARPA), via IARPA R&D Contract No.
2014-14071600012.
 Download Paper
Download Paper